
Hoje vou sair ligeiramente da minha zona de conforto e me arriscar no mundo Python. Não é uma linguagem que possuo intimidade mas por ter tido contato com algumas bibliotecas relacionadas a Inteligência Artificial, fiquei interessado em aprender mais sobre a mesma. Neste post vou mostrar como disponibilizar uma API REST criada com Python e o microframework web Flask no serviço Heroku, e o melhor: de forma 100% gratuita!
Essa história recente com o python começou com uma necessidade pessoal. Eu queria criar uma página web que exibisse diariamente os filmes que estão em cartaz nos cinemas brasileiros, a ideia em si é bem simples e jurava que ia encontrar algum site ou blog que liberasse um Feed RSS, serviço REST ou web service de forma atualizada e de fácil consulta, mas me decepcionei com o que encontrei que muitas vezes trazia apenas o que existia em outros países, ou era algum projeto no Github que estava há alguns anos sem atualização ou simplesmente não funcionava.
Partindo deste ponto, cansei de procurar e resolvi criar um serviço REST que retornasse um JSON com a lista de filmes em cartaz nos cinemas brasileiros. Para isso precisava pegar estas informações de algum site/blog que estivesse sempre atualizado. Então a missão é:
- Encontrar uma lista de filmes pública, de fácil acesso e atualizada.
- Preparar o ambiente com VsCode, Python e /módulos necessários.
- Código web do Flask
- Fazer o parse do HTML da fonte usando Python para separar apenas as informações pertinentes aos filmes em cartaz.
- Transformar essa saída em um JSON
- Disponibilizar o código-fonte no Github
- Publicar no Heroku para acesso público
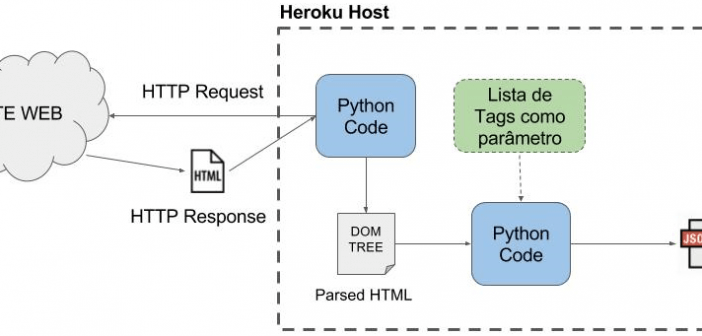
Pode parecer muita coisa mas é simples, o esquema da imagem abaixo mostra o que desejo conseguir.


1. ENCONTRAR A LISTA DE FILMES ONLINE
Existem vários no país mas acabei escolhendo o AdoroCinema por já conhecer e gostar bastante, a lista neste link, por exemplo, traz os filmes em cartaz. No momento que crie esse post, Guardiões da Galáxia 2 no topo. I’m groot!
2. PREPARAR O AMBIENTE
Já temos a fonte dos dados precisamos carregar essa página no nosso app Python, percorrer o HTML e coletar os dados que queremos. A lib que vai fazer esse trabalho pesado para nós é a BeautifulSoup, ela vai além de apenas ler um HTML, ela permite fazer parse de outros formatos também e gerar uma árvore dos dados, serve ao nosso propósito.
Fiz tudo usando o Visual Studio Code versão 1.11 mas fique a vontade para usar outro editor de código. A versão do Python que tenho instalada é a 3.5.3 e as versões das bibliotecas usadas foram as seguintes:
beautifulsoup4==4.5.3
Flask==0.12
Para instalar as duas libs acima, usei o gerenciador de módulos pip, que faz o mesmo trabalho que o npm no Node.js. Basta executar os comando abaixo na linha de comando:
pip install beautifulsoup4pip install Flask
E para quem usar o VSCode recomendo a extensão donjayamanne.python para auxiliar no desenvolvimento, mas é um extra. Para instalar execute o comando abaixo no VSCode ou use o gerenciador de extensões:
ext install python
Pode ser que no momento que estejam lendo este post já existam versões mais recentes do Python, do Visual Studio Code e das libs mostradas. Caso queira testar se o python está funcionando, crie um arquivo “teste.py” com o código abaixo:
#1
from bs4 import BeautifulSoup
#2
import urllib.request
#3
soup = BeautifulSoup('Extremely bold',"html.parser")
#4
tag = soup.b
#5
print(tag['class'])Agora execute usando o comando “python teste.py” no cmd ou pelo VSCode. A saída irá mostrar: [‘boldest’]. O que foi feito aqui foi:
#1 – Importar a biblioteca beautifulSoup
#2 – Importar a biblioteca urllib( chamada http)
#3 – Passar manualmente um HTML para ser feito o parse para o método BeautifulSoup
#4 – Carregar a tag do DOM como um objeto para a variável python “tag”
#5 – Exibir o atributo class do objeto capturado. Neste caso “boldest”
3. CÓDIGO WEB DO FLASK
O exemplo do tópico 2 mostra o funcionamento geral do que iremos fazer a partir daqui, mas existem alguns detalhes adicionais que vou explicar no código a seguir.
#PARTE1
from flask import Flask, jsonify, request
from bs4 import BeautifulSoup
from urllib.request import urlopen, Request
import os
#PARTE2
app = Flask(__name__)
#PARTE3
@app.route('/api/v1/filmes', methods=['GET'])
def filmes():
#MEU CÓDIGO AQUI
return"Tudo pronto!"
#PARTE4
if __name__ == '__main__':
port = int(os.environ.get('PORT', 5000))
app.run(host='127.0.0.1', port=port)#PARTE1: carregamos todos os módulos necessários, existem três carinhas aqui que ainda não tinha comentado: jsonify e os. Eles já vem com a instalação padrão do Python e usaremos para transformar um array para o formato JSON e para acessar as portas do nosso ambiente no Heroku respectivamente.
#PARTE2: esse trecho simplesmente cria um app web usando Flask. A variável app recebe o objeto Flask. Usaremo a variável app mais abaixo para criar a rota e iniciar nosso serviço.
#PARTE3: com app.route dizemos qual o caminho de acesso e qual verbo HTTP será utilizado. Neste caso estamos apenas retornando uma lista de elementos então será criado um GET no caminho “/api/v1/filmes“, que fica ao seu critério escolher. Em sequencia definimos uma função que será chamada ao acessar esse caminho, dentro dela terá apenas um return com a string “Tudo pronto!” por enquanto, no próximo tópico veremos o código que ficará neste local.
#PARTE4: agora definimos alguns parâmetros de ambiente, a variável port recebe uma porta disponível ou a 5000 por padrão, a lib os cuida disso. Precisei deixar dessa forma para funcionar no Heroku. O mesmo vale para o host, quando rodo local uso 127.0.0.1(localhost) mas quando publico no Heroku preciso colocar 0.0.0.0 para funcionar, nos bastidores ele irá setar o host correto.
Simples né? Isto foi apenas para testar e montar nosso ambiente base, vamos agora carregar o HTML do site AdoroCinema e capturar informações de verdade.
4. FAZER O PARSE DO HTML
Vamos agora carregar os dados dos filmes direto da página online do AdoroCinema, a estrutura HTML do link http://www.adorocinema.com/filmes/numero-cinemas/ é esta:


O site traz vários blocos como este mostrado na imagem acima, um embaixo do outro. Se conseguirmos trazer as informações de um bloco trazer dos outros é trivial. Os dados que queremos são:
- Nome do filme
- Data de Lançamento
- Sinopse
- Imagem do poster
Veja que cada um dos elementos eu circulei em vermelho e coloquei ao lado o nome da variável referente a eles que será utilizado no código em Python. Para capturar os dados precisamos da tag do DOM no HTML para passar como parâmetro para a biblioteca BeautifulSoup, a ferramenta perfeita para isso é o Inspetor de Elementos do navegador, todos os browsers atuais possuem um, seja Chrome, Firefox ou MS Edge. Veja um exemplo:


A linhas que irão capturar os valores de cada tag e armazenar em um vetor são:
#PARTE1
html_doc = urlopen("http://www.adorocinema.com/filmes/numero-cinemas/").read()
soup = BeautifulSoup(html_doc, "html.parser")
#PARTE2
data = []
for dataBox in soup.find_all("div",class_="data_box"):
nomeObj = dataBox.find("h2", class_="tt_18 d_inline").find("a", class_="no_underline")
imgObj = dataBox.find(class_="img_side_content")
sinopseObj = dataBox.find("div", class_="content").find("p")
dataObj = dataBox.find("ul", class_="list_item_p2v tab_col_first").find("div", class_="oflow_a")
#PARTE3
data.append({ 'nome': nomeObj.text.strip(),
'poster' : imgObj.img['src'].strip(),
'sinopse' : sinopseObj.text.strip(),
'data' : dataObj.text.strip()})5. GERAR A SAÍDA EM JSON
O pior já passou, agora é só transformar nosso vetor data que possui a lista de objetos(filmes), para o formato JSON. No return colocamos a linha abaixo:
return jsonify({'filmes': data})6. COMPARTILHANDO NO GITHUB
Antes de colocar no Heroku o projeto foi disponibilizado no Github no endereço abaixo. O motivo é que uma das formas que o Heroku permite fazer o deploy da app é através da integração com o Github o que é bem mais prático.
https://github.com/rodrigorf/filmes-cartaz-json
7. PUBLICANDO A API NO HEROKU
Antes de colocarmos no Heroku precisamos criar três arquivos de configuração que o servidor precisa, acabei descobrindo isso após me bater bastante ao subir o projeto da primeira vez. Os arquivos na raíz do projeto são Procfile, requirements.txt e runtime.txt.
- requirements.txt -> informa os módulos que devem ser importados no servidor para que a aplicação funcione, são eles: beautifulsoup4==4.5.3 e Flask==0.12.
- runtime.txt -> informa a versão do python que queremos rodar: python-3.4.3.
- Procfile -> arquivo que contém o comando de execução e o nome da app, desta forma -> web: python web.py
A aplicação esta versionada e já retorna a lista de filmes em formato JSON, isto já deve servir para muitas pessoas mas a ideia era criar algo que outros possam usar sem precisar necessariamente clonar um repositório no Github e compilar uma app em Python. Meu objetivo principal é ter uma URL pública que outros desenvolvedores possam utilizar também seja em Python, C#, Node.js, Java, ou qualquer linguagem. Vamos agora publicar em nossa hospedagem, o http://heroku.com, siga os passos abaixo:
- Crie uma conta no site do Heroku.
- Faça o login no seu painel em https://dashboard.heroku.com


Tela inicial do painel do Heroku
3. Clique em “Create new app”.
4. Na tela seguinte informe um nome e a região do servidor.
5. Ao avançar seremos levados diretamente a tela de deploy da app. Aqui faremos a conexão com o Github conforme imagem abaixo.


Escolhemos conectar com Github para pegar o código-fonte da app.
6. Clique em Github e autorize a conexão do Heroku. A aba abaixo é mostrada, procure o projeto em seus repositórios e clique em “Connect”.


Conexão com o repositório do app que criamos
Lembrando que para que for fazer isso deverá primeiro clonar o projeto no Github.
7. Estando tudo certo e devidamente conectados com o Github já podemos fazer o deploy. O deploy pode ser automático, ou seja, todo push feito no branch dispara uma publicação, ou ser feito de forma manual. No nosso caso será manualmente.


8. Ao clicar em “Deploy Branch” o processo de carregamento do aplicativo será iniciado e um log do processo é mostrado, o Python é configurado, o PIP bem como os módulos existentes são instalados no servidor para que a aplicação funcione.


Caso tudo termine sem erros, é apresentada uma mensagem de sucesso e um botão para exibir a aplicação.


Clique em “View” para abrir a URL da sua aplicação, algo do tipo https://minhaapp.herokuapp.com. Verá uma mensagem de “NOT FOUND” isto ocorre pois criamos uma rota específica para nosso GET que retorna os filmes, lembra? o caminho da rota é “/api/v1/filmes”, então fica:
https://minhaapp.herokuapp.com/api/v1/filmes
Finalmente é apresentado nosso JSON com a lista dos filmes carregadas em tempo real. Olha só que legal:


Caso a exibição no Chrome não esteja do seu gosto, eu instalei uma extensão chamada Json Viewer que permite aplicar alguns temas e formatar melhor o JSON. Bom é isso galera, o post ficou um pouco extenso pois tentei descrever da melhor forma possível cada passo.
Em breve quero deixar o projeto mais flexível para facilitar o carregamento a partir de outras fontes de filmes, a ideia basicamente é criar um arquivo JSON de configuração onde o usuário informa apenas a URL e os XPATH de onde cada dado será puxado, por exemplo, para o AdoroCinema ficaria assim:
{
"url":"http://www.adorocinema.com/filmes/numero-cinemas/",
"pathNome":"//*[@id='col_main']/div[6]/div/div/div[1]/h2/a",
"pathData":"//*[@id='col_main']/div[6]/div/div/ul/li[1]/div",
"pathSinopse":"//*[@id='col_main']/div[6]/div/div/p",
"pathPoster":"//*[@id='col_main']/div[6]/div/a/img"
}Infelizmente a BeautifulSoup não dá suporte direto para XPath, talvez consiga fazer isso com a lib lxml, mas o bacana desse modelo é que qualquer um com um navegador moderno pode capturar o xpath a partir do inspetor de elementos e criar um JSON de configuração, permitindo que a própria comunidade crie as mais variadas fontes de filmes sem muito esforço.
Quem quiser contribuir com o projeto fique a vontade para dar um fork lá e vamos trabalhando juntos. Até a próxima.