
Já não é mais novidade ouvir sobre serverless nos dias de hoje quando falamos sobre construção de aplicações cloud native e distribuídas. Porém, vamos abordar neste artigo sobre uma tendência que vem ganhando espaço no mundo dos bancos de dados: o bancos de dados serverless. Para compartilhar com vocês sobre um pouco do que rola no meu ambiente de trabalho, vamos focar na ferramenta MongoDB Serverless, que tem conquistado muitos desenvolvedores. Então, senta aí e se liga nas dicas!
Tá, mas o que é serverless e como isso se aplica a banco de dados?
Primeiro, vamos entender o que é um banco de dados Serverless. Basicamente, é um modelo em que o provedor de nuvem cuida de toda a infraestrutura, escalabilidade e gerenciamento do banco de dados. Isso significa menos preocupações para os desenvolvedores e mais tempo para focar no que realmente importa: o desenvolvimento do aplicativo!
Nesse modelo, os recursos computacionais são alocados dinamicamente conforme a demanda, o que torna o sistema altamente escalável e flexível. Os bancos de dados serverless também seguem um modelo de pagamento baseado no consumo, o que significa que você paga apenas pelos recursos efetivamente utilizados e pelo armazenamento, sem a necessidade de reservar capacidade fixa.
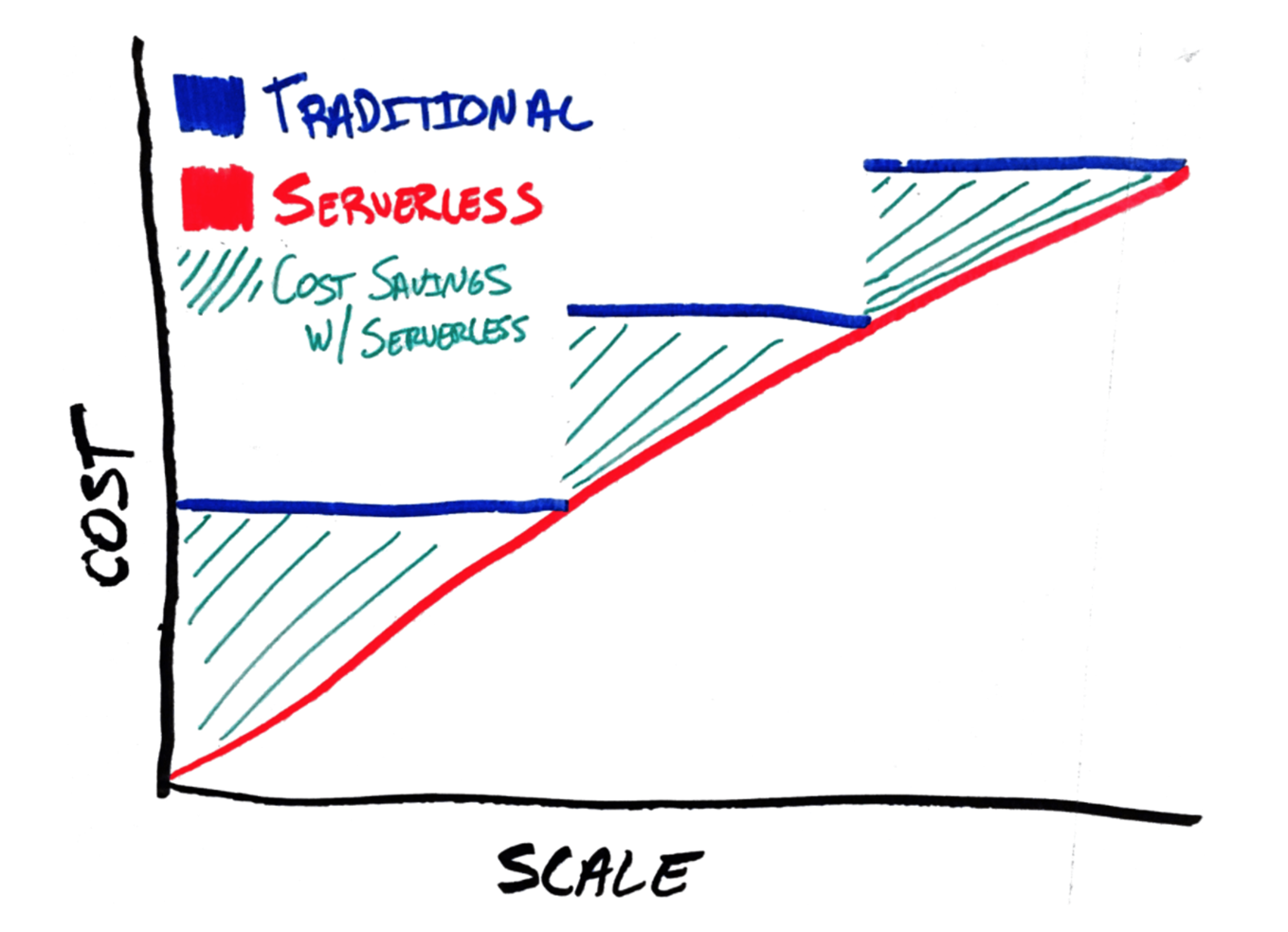
Vamos imaginar um cenário do mundo real para ajudar a comparar o banco de dados serverless com o banco de dados como serviço (DBaaS) tradicional:
Buffet de comida por kilo vs. Restaurante à la carte
Pense no banco de dados serverless como um buffet de comida. Você paga pelo que consome, e a quantidade e variedade de pratos disponíveis são ajustadas automaticamente conforme a demanda dos clientes. Se muitos clientes aparecerem de repente, o buffet adiciona mais pratos e opções e você só paga pelo que colocar no prato.
Por outro lado, um DBaaS tradicional é como um restaurante à la carte. Você escolhe um prato específico (ou seja, a capacidade do servidor) e paga um preço fixo por ele, independentemente de comer tudo ou apenas uma parte. A capacidade do restaurante (ou seja, o servidor) é limitada, e se você precisar de mais, precisará pedir e pagar por mais pratos.
Em resumo, você paga pelo consumo e não custos fixos relacionados a tamanho de instâncias
Prós e contras sobre o uso de serverless
Após alguns meses utilizando MongoDB serverless em produção para um microsserviço que construímos, conseguimos encontrar alguns prós e contras que quero compartilhar com vocês:
Prós:
- Escalabilidade automática: A grande vantagem do serverless é que ele escala automaticamente conforme a demanda, sem a necessidade de provisionar recursos manualmente.
- Custos flexíveis: Você só paga pelo que usa! Em vez de pagar por uma instância fixa, o custo é baseado no consumo de recursos, como armazenamento, solicitações e tráfego de rede.
- Facilidade de gerenciamento: Você ainda continua com a facilidade de gerenciamento de um banco SaaS.
- Mesma API: Não precisa fazer nenhuma modificação no seu código, basta escolher o seu cluster serverless preferido, colocar a connection string e sair usando.
Contras:
- Limitações de recursos: Embora a escalabilidade automática seja uma vantagem, às vezes você pode se deparar com limitações do provedor, como limites de capacidade ou tempo de execução. Exemplo: o MongoDB serverless ainda não está disponível no Brasil e também não aceita bancos de dados maiores do que 1TB. Tudo isso precisa ser levado em conta quando for escolher um produto assim.
- Custo em cenários de alta utilização: Se sua aplicação tiver um uso constante e pesado, o modelo de pagamento baseado em consumo pode acabar sendo mais caro do que um modelo fixo.
- Falha humana ou de processo: Caso algum script faça requisições em demasia, você sobre algum ataque DDOs não tratado via WAF ou algo similar, você vai ser cobrado por isso e acredite, você não vai gostar de entrar em um cenário assim.
- Latência: Em alguns casos, a latência pode ser maior em ambientes serverless, especialmente se houver uma chamada “cold start” (quando a função não foi usada recentemente e precisa ser “aquecida”).
Quando você deve usar a computação sem servidor?
- Você não sabe qual escala de carga de trabalho esperar
- Você não quer pagar por recursos não utilizados
- DB’s com padrões de uso intermitentes e imprevisíveis intercalados com períodos de inatividade e menor utilização média de computação ao longo do tempo.
- DB’s que são frequentemente reescalonados e clientes que preferem delegar o reescalonamento de computação para o serviço.
- Você deseja evitar o gerenciamento de infraestrutura o máximo possível
- Você deseja hospedar um back-end de aplicativo inteiro em uma plataforma gerenciada
- Você precisa de um pequeno pedaço de funcionalidade personalizada em um fluxo de trabalho de outros serviços
Tá, mas quanto custa?
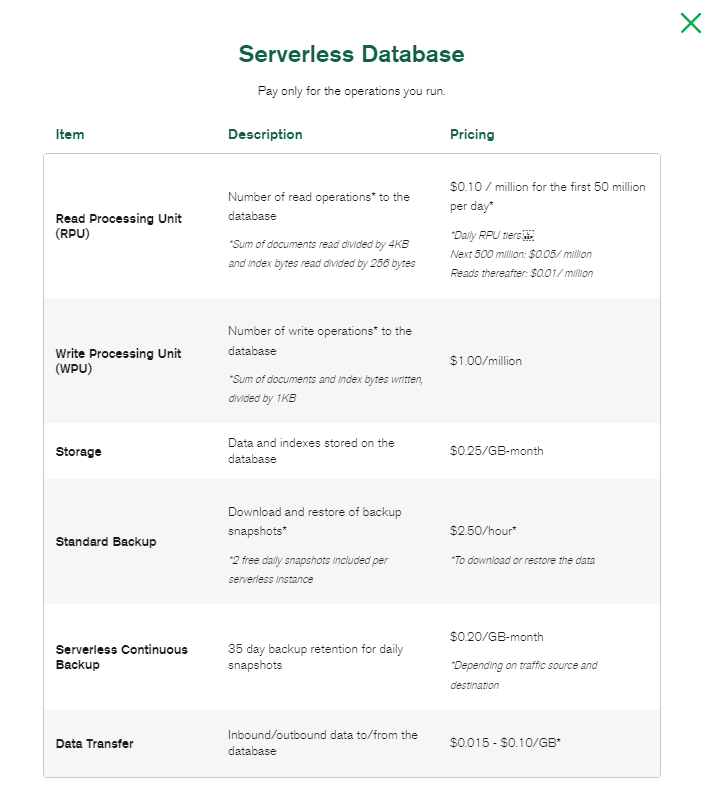
Em relação ao preço, o MongoDB Serverless oferece um modelo de pagamento baseado no uso de recursos, como solicitações, armazenamento e largura de banda. Isso pode ser bastante econômico para muitos casos de uso, especialmente aqueles com tráfego variável. O preço inicial, é de 0.10 dólares a cada 1 milhão de leituras.
O que eu posso recomendar para você após 6 meses rodando o projeto?
- Modelagem ainda é uma preocupação. “Garbage in, garbage out”.
- Parece óbvio, mas você paga pelos testes de carga.
- Use e abuse da paginação feita direto no banco. $skip e $limit são seus amigos.
- Coloque alertas! Alertas de billing, de consumo, erros e latência.
- Persistência poliglota sempre, um bom serviço de cache ajuda muito na performance e redução de custos!
- Mantenha seu driver atualizado, melhorias sempre surgem e você precisa aproveitar isso.
- Considere o tempo de latência em ambientes produtivos, isso em larga escala pode fazer bastante diferença!
Bom, por hora é isso! Até o momento, acredito nesta iniciativa, principalmente para ambientes de homologação ou de acesso muito esporádico. Acreditamos que para ambientes produtivos massivos, continuaremos utilizando instâncias por enquanto.
Em breve, voltarei aqui para trazer atualizações sobre esta ferramenta.