
Em um cenário cada vez mais dominado por arquiteturas baseadas em microservices, garantir a resiliência e o desempenho dos sistemas diante de sobrecargas e falhas é um desafio técnico constante. Dentre as estratégias fundamentais para mitigar esses riscos estão dois padrões consagrados: back-pressure e bulkhead.
Este artigo apresenta os fundamentos desses dois mecanismos, seus benefícios, cenários de aplicação e como implementá-los de forma eficaz em sistemas distribuídos modernos.
Por que sistemas quebram sob pressão?
Microsserviços frequentemente se comunicam em cadeia: uma requisição feita ao frontend pode desencadear chamadas a diversos serviços internos, que por sua vez dependem de bancos de dados, caches, serviços externos e filas. Em situações de alta carga ou falha em um serviço intermediário, o efeito dominó pode causar saturação de recursos, timeouts, aumento de latência e eventualmente quedas generalizadas.
Para lidar com esse cenário, precisamos de mecanismos que atuem tanto preventivamente quanto reativamente, desacoplando partes do sistema e controlando o fluxo de requisições.
Back-pressure: quando dizer “não” salva o sistema
Back-pressure é uma técnica usada para sinalizar que um sistema ou componente está sobrecarregado e precisa que os upstreams (serviços anteriores na cadeia) desacelerem ou parem de enviar requisições temporariamente.
Como funciona?
Em um pipeline de processamento, o consumidor (serviço downstream) pode notificar o produtor (upstream) de que não consegue mais processar mensagens no ritmo esperado. Isso pode ser feito por:
- Limites de filas internas (buffer cheio)
- Sinais de erro explícitos (ex: HTTP 429 Too Many Requests)
- Mecanismos reativos (ex:
Flowable,Publishercom back-pressure em RxJava, Reactor, Akka Streams) - Inserção de um sistema de filas intermediárias (ex: RabbitMQ, Kafka, SQS), que absorve picos de carga e atua como uma zona de amortecimento entre serviços — ajudando o sistema a manter o ritmo de consumo sob controle Em um pipeline de processamento, o consumidor (serviço downstream) pode notificar o produtor (upstream) de que não consegue mais processar mensagens no ritmo esperado. Isso pode ser feito por:
- Limites de filas internas (buffer cheio)
- Sinais de erro explícitos (ex: HTTP 429 Too Many Requests)
- Mecanismos reativos (ex:
Flowable,Publishercom back-pressure em RxJava, Reactor, Akka Streams)
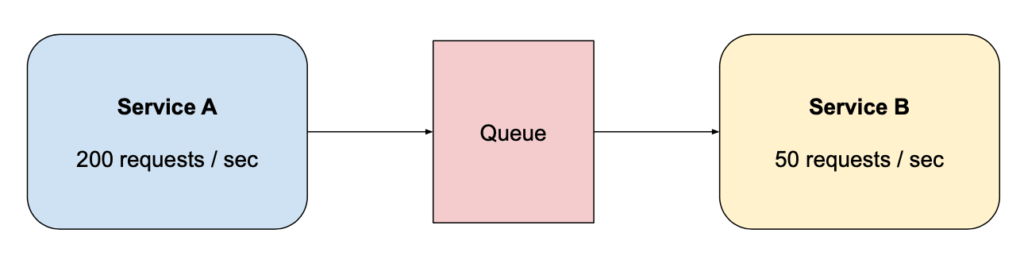
Benefícios:
- Protege serviços críticos de colapsar por excesso de carga
- Evita uso excessivo de CPU, memória e I/O
- Reduz acúmulo de mensagens e latência em cascata
Exemplo:
Um serviço de checkout que depende de um serviço de recomendação pode aplicar back-pressure se o tempo médio de resposta da recomendação ultrapassar um limite, respondendo com dados parciais ou fallback ao invés de manter o usuário esperando indefinidamente.
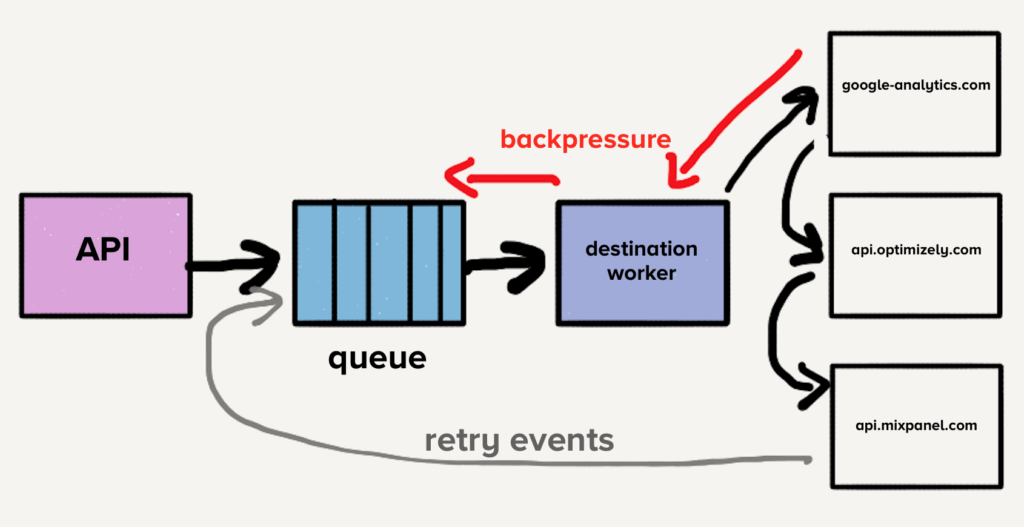
Outro exemplo clássico é o uso de filas intermediárias entre sistemas, como mostra a imagem abaixo. Imagine uma API que publica eventos para múltiplos serviços de analytics. Esses eventos são colocados em uma fila e processados por um worker que envia dados para destinos externos como Mixpanel ou Google Analytics. Quando algum desses destinos começa a responder lentamente, o worker desacelera, a fila enche, e o sistema aplica back-pressure para sinalizar a sobrecarga ao produtor (API). Isso evita que o sistema acumule requisições em cascata e permite que componentes upstream reajam à sobrecarga.
Bulkhead: isolamento de falhas como estratégia de contenção
Uma dúvida comum é entender a diferença entre aplicar o padrão Bulkhead e simplesmente escalar horizontalmente ou utilizar um balanceador de carga. Embora estejam todos relacionados à confiabilidade e desempenho, os objetivos e os efeitos dessas abordagens são distintos:
- Escalar horizontalmente consiste em adicionar mais instâncias de um serviço para lidar com um volume maior de requisições. Isso melhora a capacidade total do sistema, mas não evita que todos os recursos sejam consumidos por uma única funcionalidade ou cliente específico.
- Load balancing distribui requisições entre instâncias disponíveis, promovendo eficiência e reduzindo pontos de falha únicos. No entanto, ele não isola recursos por tipo de operação, cliente ou rota. Uma carga excessiva em uma funcionalidade pode ainda afetar outras.
- Bulkhead, por outro lado, atua dentro da própria instância do serviço, garantindo que recursos como threads, conexões ou filas estejam compartimentalizados. Isso significa que mesmo que você escale ou balanceie a carga, o bulkhead assegura que falhas localizadas ou picos de uso em uma parte da aplicação não comprometam outras partes.
Em resumo:
- Escalar aumenta a capacidade;
- Load balancer distribui a carga;
- Bulkhead impede que partes da aplicação se prejudiquem mutuamente sob falha ou sobrecarga.
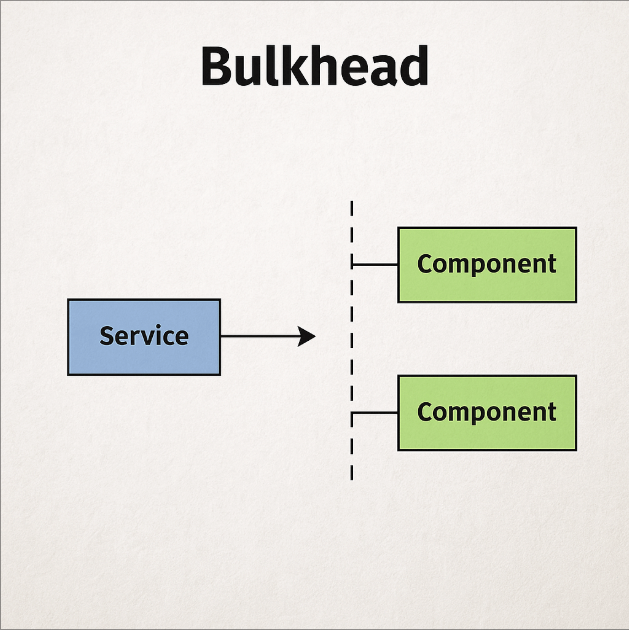
O padrão Bulkhead, inspirado nos compartimentos estanques de navios, é uma estratégia de resiliência que visa limitar o impacto de falhas e sobrecarga, impedindo que elas se propaguem para outras partes do sistema. Em sistemas distribuídos, esse padrão é fundamental para evitar que a saturação de um componente ou serviço afete todo o ecossistema.
Como funciona?
A ideia é dividir os recursos — como threads, memória, conexões e até mesmo circuitos de execução — em compartimentos independentes. Assim como em um navio um vazamento não afunda toda a embarcação por conta dos compartimentos selados, no seu sistema uma falha localizada também não deve derrubar tudo.
Técnicas comuns:
- Pools de threads dedicados: alocar threads separadas para processar requisições de diferentes serviços ou funcionalidades.
- Separação de filas: cada rota ou módulo do sistema tem sua própria fila de requisições.
- Semáforos com cotas por domínio: limitar o número de acessos simultâneos por cliente, rota ou endpoint.
- Circuit breakers isolados por funcionalidade: para evitar que falhas persistentes afetem caminhos não relacionados.
Exemplos práticos:
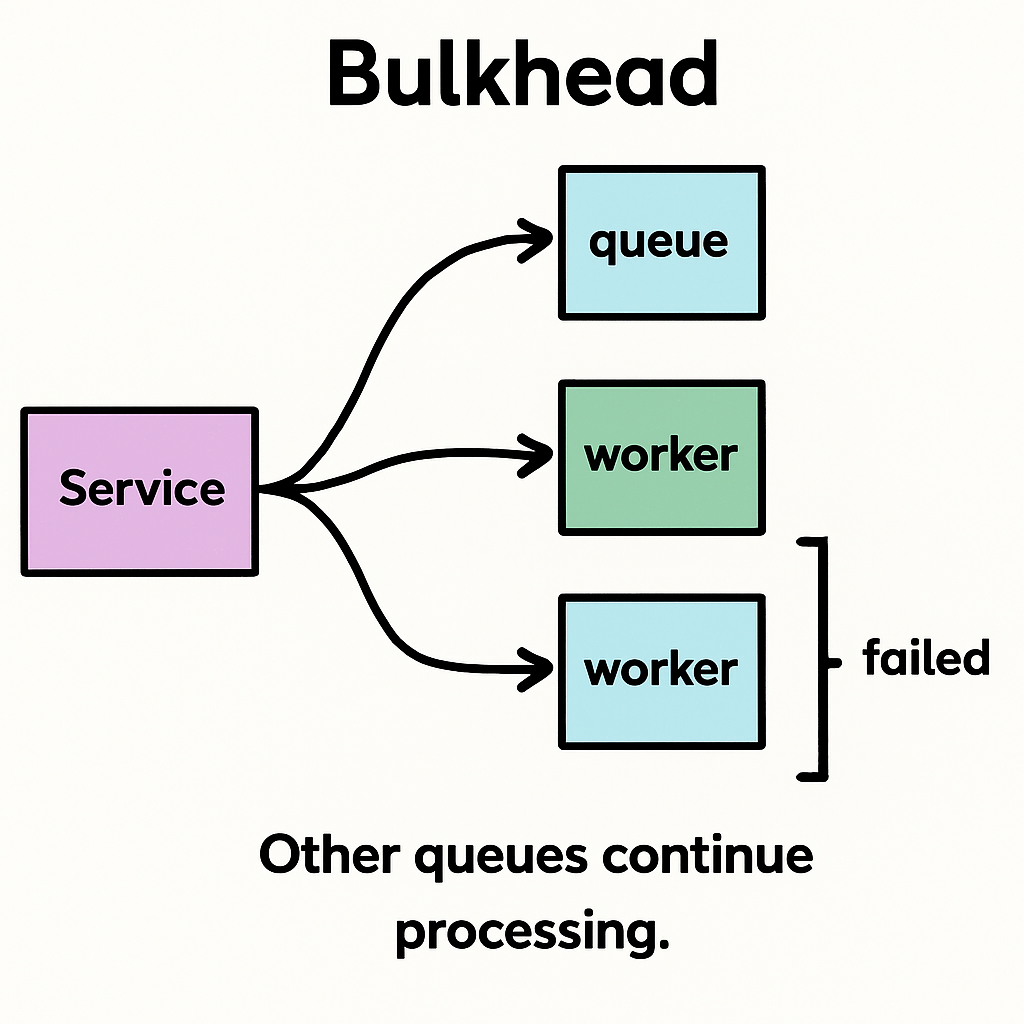
- Um sistema de e-commerce com três funcionalidades críticas: checkout, upload de imagem e chat com vendedor. Ao aplicar o padrão bulkhead, cada funcionalidade roda com um pool de threads independente. Mesmo que o upload de imagens fique lento ou indisponível (por exemplo, devido a problemas no armazenamento em nuvem), ele não consome os recursos necessários para o checkout — mantendo a compra funcional.
- Uma API pública que atende parceiros estratégicos e clientes comuns. O bulkhead pode ser aplicado criando limites independentes de requisições simultâneas para cada tipo de consumidor. Assim, um pico de tráfego causado por um cliente comum não interfere na operação dos parceiros críticos.
- Uma aplicação que executa tarefas assíncronas pode alocar diferentes workers ou filas por tipo de tarefa (ex: geração de relatórios, notificações por e-mail, sincronização de dados). Se a fila de relatórios for sobrecarregada, as notificações e sincronizações seguem funcionando normalmente.
Benefícios:
- Redução de efeitos colaterais causados por falhas locais
- Maior previsibilidade sob cenários de carga desigual
- Evita o esgotamento global de recursos
- Ajuda a manter SLAs mesmo durante degradações parciais
Quando aplicar?
Sempre que diferentes partes do seu sistema compartilham recursos, e você precisa garantir que a falha ou lentidão de uma não prejudique a outra. É especialmente útil quando há variações imprevisíveis de carga, requisitos de SLA distintos ou modularidade clara entre componentes. Um sistema que processa uploads de arquivos e pedidos de compra pode definir limites independentes de threads para cada rota. Assim, se o endpoint de uploads ficar lento por causa de arquivos grandes, ele não impede que pedidos sejam concluídos normalmente.
Quando aplicar cada um?
| Cenário | Back-pressure | Bulkhead |
|---|---|---|
| Servidor sob carga excessiva | ✅ | – |
| Serviço externo instável | ✅ | ✅ |
| Proteção de SLA por funcionalidade | – | ✅ |
| Pipeline de dados reativo | ✅ | – |
| Concorrência em tarefas pesadas | – | ✅ |
Integração com outras técnicas de resiliência
- Circuit Breaker: pode ser combinado com bulkhead para impedir que falhas reincidentes afetem o sistema.
- Rate Limiting: trabalha do lado do consumidor, limitando o número de requisições — complementando o back-pressure que atua no lado produtor.
- Retry com jitter: pode coexistir com back-pressure, mas deve ser cuidadosamente configurado para não piorar a sobrecarga.
Considerações finais
Projetar sistemas resilientes vai além de tratar exceções: é necessário criar barreiras e canais de escape antes da falha acontecer. Back-pressure e bulkhead são estratégias comprovadas para proteger sua arquitetura contra falhas sistêmicas causadas por sobrecarga, concorrência descontrolada e efeitos de propagação.
Ao aplicá-los corretamente, você melhora a previsibilidade, reduz riscos operacionais e entrega experiências mais confiáveis para seus usuários — mesmo quando o sistema está sob pressão.