




Este artigo é uma continuação do nosso tutorial sobre os primeiros passos com o MongoDB Atlas Search, os primeiros artigos são, neles você vai encontrar uma base mais teórica para o que iremos praticar neste artigo. Você pode encontrá-los aqui:
No artigo anterior, exploramos os conceitos básicos e a implementação do Atlas Vector Search no MongoDB Atlas, destacando sua utilidade e versatilidade em busca de vetores. Agora, vamos avançar para um nível mais complexo e interessante: a integração do Atlas Search com .NET, utilizando Vector Search e o poder do ChatGPT para aprimorar ainda mais nossas capacidades de busca e análise de dados.
Neste tutorial, você aprenderá como adicionar pesquisa vetorial com MongoDB Atlas Vector Search, usando o Driver MongoDB C#, para uma aplicação .NET Blazor, que por sinal é a mesma do artigo passado. A aplicação usará o banco de dados sample_mflix, disponível no conjunto de dados de amostra que qualquer pessoa pode carregar em seu cluster Atlas. Mas diferentemente do artigo anterior, vamos precisar dos dados embedados, por isto iremos utilizar um outro dataset.
Colocando nossos dados embedados no Atlas
A primeira coisa que você precisa é de alguns dados armazenados em seu cluster que tenham vetores embedados (vector embeddings) disponíveis como um campo em seus documentos. O MongoDB já forneceu uma versão da coleção de filmes do sample_mflix, chamada embedded_movies, que possui 1.500 documentos, usando um subconjunto da coleção principal de filmes que foi carregado como um conjunto de dados para Hugging Face que será usado neste tutorial.
O que são incorporações vetoriais?
Um vetor é uma lista de números de ponto flutuante (representando um ponto em um espaço de incorporação n-dimensional) e captura informações semânticas sobre o texto que representa. Por exemplo, uma incorporação para a string “MongoDB é incrível” usando um modelo LLM de código aberto chamado all-MiniLM-L6-v2 consistiria em 384 números de ponto flutuante e teria a seguinte aparência:
[-0.018378766253590584, -0.004090079106390476, -0.05688102915883064, 0.04963553324341774,
0.08254531025886536, -0.07415960729122162, -0.007168072275817394, 0.0672200545668602]
Por hora, basta saber que o vector embedding é apenas uma “conversão” de uma informação para um vetor com números flutuantes. É quase (bem quase) uma conversão hexadecimal ou binária.
Para esta primeira etapa do processo, faça a utilização deste repositorio: Hugging Face Dataset Upload tool e o execute localmente para popular seu cluster. Neste tutorial, iremos utilizar a API da OpenAI (o famoso chatgpt), mas você pode gerar embeddings vetoriais para seus próprios dados usando ferramentas como Hugging Face, OpenAI, LlamaIndex e outras.
Criando o índice de pesquisa vetorial
Agora que você tem uma collection de documentos de filmes com um campo plot_embedding, é hora de criar o índice Atlas Vector Search. Isso permite habilitar recursos de pesquisa vetorial no cluster e permitir que o MongoDB saiba onde encontrar os embeddings vetoriais. O processo de criação do índice é bem similar aos outros índices do Atlas Search
1- Acesse o seu cluster e clique na aba Atlas Search


2 – Selecione o tipo Atlas Vector Search

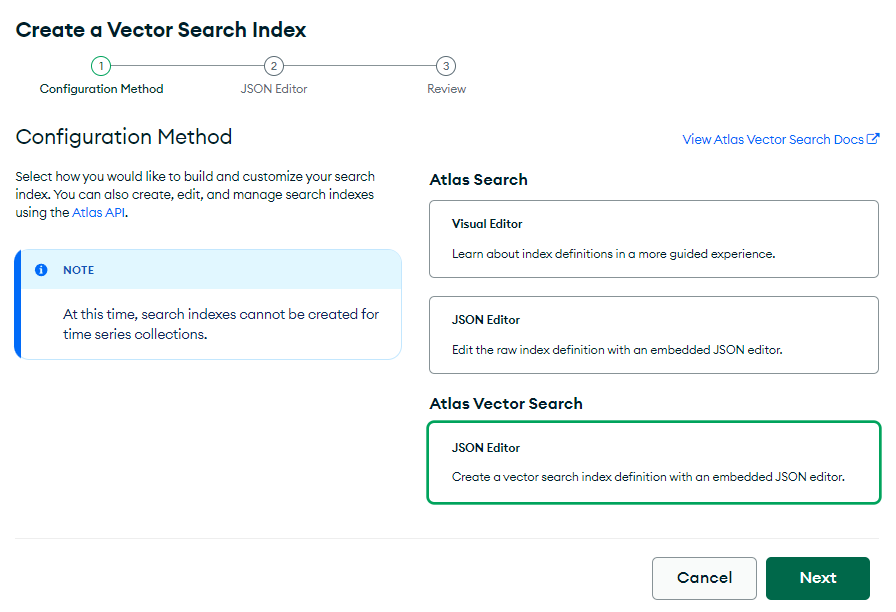
3 – Selecione a coleção embedded_movies em sample_mflix à esquerda. O nome não importa muito aqui, contanto que você se lembre dele para mais tarde, mas por enquanto, deixe-o como o valor padrão de ‘vector_index’.
4 – Copie e cole o seguinte JSON, substituindo o conteúdo atual da caixa no assistente:
{
"fields": [
{
"type": "vector",
"path": "plot_embedding",
"numDimensions": 1536,
"similarity": "dotProduct"
}
]
}
|
Este JSON contém alguns campos que você talvez não tenha visto antes.
- path é o nome do campo que contém os embeddings. No caso do conjunto de dados do Hugging Face, é plot_embedding.
- numDimensions refere-se às dimensões do modelo utilizado.
- similaridade refere-se ao tipo de função usada para encontrar resultados semelhantes.
Confira a Documentação do Atlas Vector Search para saber mais sobre esses campos de configuração.
Clique em “Avançar” e na próxima página, clique em “Criar índice de pesquisa”. Após alguns minutos, o índice de pesquisa vetorial será configurado, você será notificado por e-mail e sua aplicação estará pronto para adicionar a pesquisa vetorial.


Adicionando a funcionalidade em .NET
Agora que você tem os dados com embeddings de plotagem e um índice de pesquisa vetorial criado nesse campo, então é hora de começar a trabalhar no nossa API para adicionar pesquisa. Eu tomei liberdade e criei um repositório com tudo o que você vai precisar para rodar sua aplicação, basta acessá-la aqui: SeeSharpMovies
Antes de mais nada, você vai precisar de uma chave de API OpenAI, você pode obtê-la aqui. A chave de API permite que os programadores possam ter a capacidade de usar a API da empresa para criar as suas próprias aplicações. Esta chave é relativamente simples de obter, e qualquer utilizador com uma conta na OpenAI pode obter a mesma.
Informação importante: As chaves de APIs da OpenAI possuem um limite gratuito, porém são pagas, portanto pode ser necessário que você precise adicionar créditos na sua conta para utilizar o projeto.
Clonado o projeto, Adicione o seguinte na raiz do seu appsettings.Development.json e appsettings.json, após a seção MongoDB, substituindo o texto do espaço reservado pela sua própria chave:
{
"Logging": {
"LogLevel": {
"Default": "Information",
"Microsoft.AspNetCore": "Warning"
}
},
"AllowedHosts": "*",
"MongoDBSettings": {
"AtlasURI": "mongodb+srv://<username>:<password>@<cluster-url>/",
"DatabaseName": "sample_mflix"
},
"OpenAPIKey": "<YOUR OPENAI API KEY>"
}
|
Adicionando um método para solicitar embeddings para o termo de pesquisado
É hora de usar a chave de API do OpenAI e escrever funcionalidades para criar embeddings vetoriais para o termo pesquisado chamando o método Embeddings da OpenAI. De maneira resumida, vamos chamar a API da OpenAI com o termo pesquisado na nossa API e obter no retorno, o embedd do termo de pesquisa.
Veja abaixo um retorno via Postman, chamando a API da OpenAI

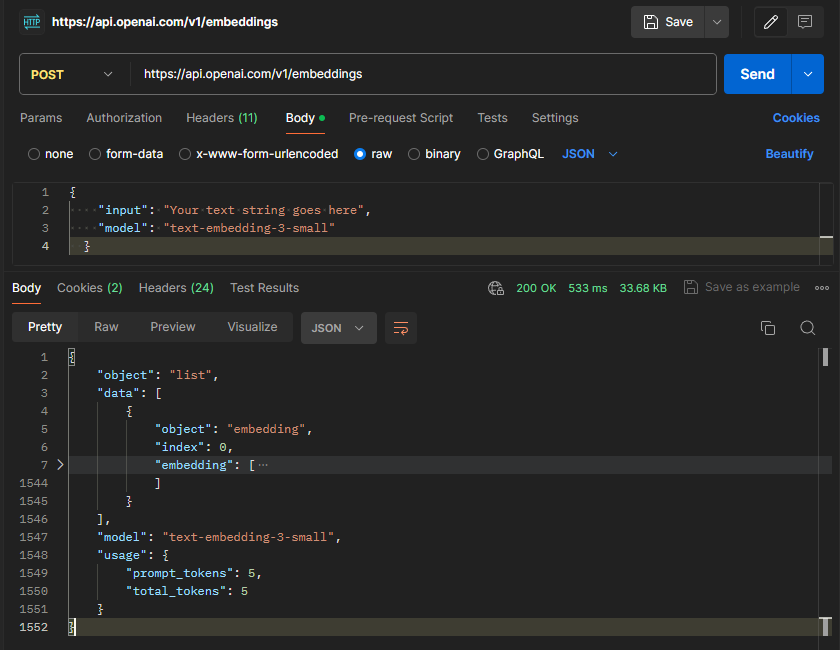
Eu recomendo fortemente que você leia a documentação da OpenAI para entender os modelos fornecidos, precificação etc. Por hora, iremos utilizar o modelo “text-embedding-ada-002” que é um modelo próprio para pequenas pesquisas textuais, que é o nosso caso.
Voltando ao código, dentro da classe MongoDBService.cs, adicione o seguinte código:
private async Task<List<double>> GetEmbeddingsFromText(string text)
{
Dictionary<string, object> body = new Dictionary<string, object>
{
{ "model", "text-embedding-ada-002" },
{ "input", text }
};
_httpClient.BaseAddress = new Uri("https://api.openai.com");
_httpClient.DefaultRequestHeaders.Add("Authorization", $"Bearer {_openAPIKey}");
string requestBody = JsonSerializer.Serialize(body);
StringContent requestContent =
new StringContent(requestBody, Encoding.UTF8, "application/json");
var response = await _httpClient.PostAsync("/v1/embeddings", requestContent)
.ConfigureAwait(false);
if (response.IsSuccessStatusCode)
{
string responseBody = await response.Content.ReadAsStringAsync();
EmbeddingResponse embeddingResponse = JsonSerializer.Deserialize<EmbeddingResponse>(responseBody);
return embeddingResponse.data[0].embedding;
}
return new List<double>();
}
|
Este método faz um post para API da OpenAI e retorna o nosso vetor embedado.
Implementando a função SearchMovie
O método GetEmbeddingsFromText retornou os embeddings para o termo de pesquisa, portanto agora ele está disponível para ser usado pelo Atlas Vector Search e pelo driver C#.
Cole o seguinte código para implementar a pesquisa:
public IEnumerable<Movie> MovieSearch(string textToSearch)
{
var vector = GetEmbeddingsFromText(textToSearch).Result.ToArray();
var vectorOptions = new VectorSearchOptions<Movie>()
{
IndexName = "vector_index",
NumberOfCandidates = 150
};
var movies = _movies.Aggregate()
.VectorSearch(movie => movie.PlotEmbedding, vector, 150, vectorOptions)
.Project<Movie>(Builders<Movie>.Projection
.Include(m => m.Title)
.Include(m => m.Plot)
.Include(m => m.Poster))
.ToList();
return movies;
}
|
Se você escolheu um nome diferente ao criar o índice de pesquisa vetorial anteriormente, certifique-se de atualizar esta linha dentro de vectorOptions.
A pesquisa vetorial está disponível dentro do driver C# como parte do pipeline de agregação. São necessários quatro parâmetros: o nome do campo com os embeddings, os embeddings do vetor do termo pesquisado, o número de resultados a serem retornados e as opções do vetor.
O projeto conta já com uma implementação básica de front-end utilizando blazor, que eu não vou cobrir neste artigo, mas que você pode encontrar aqui MongoDB Atlas Search with .NET Blazor for Vector Search
Testando a pesquisa
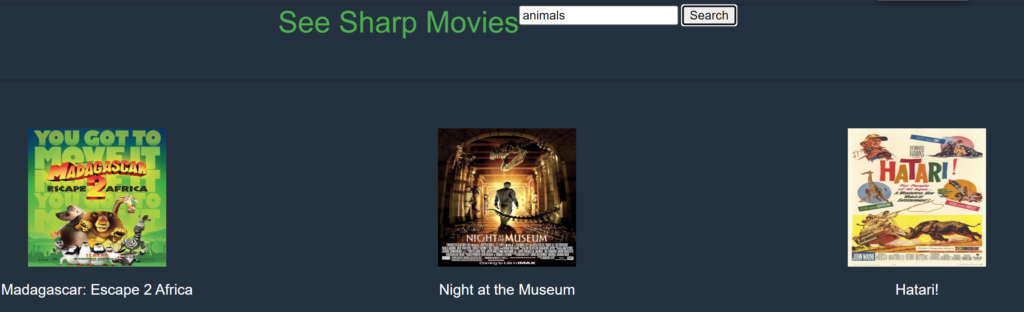
Uau! Implementamos a funcionalidade de backend, então agora é hora de executar a aplicação e vê-la em ação!
Execute o projeto, digite um termo de pesquisa na caixa, clique no botão “Pesquisar” e veja quais filmes têm enredos semanticamente próximos ao seu termo de pesquisa. No meu caso eu digitei “Animals” e o primeiro filme a vir, foi o Madagascar! Impressionante, não é?

Resumo
Incrível! Agora você tem um aplicativo Blazor em .NET funcional com a capacidade de pesquisar o contexto por significado em vez de texto exato. Este também é um excelente ponto de partida para implementar mais recursos de pesquisa vetorial em seus projetos. Se você quiser saber mais sobre o Atlas Vector Search, você pode ler a documentação oficial. O MongoDB também possui um espaço no Hugging Face onde você pode ver alguns mais exemplos do que pode ser feito e até brincar com isso.
Com isto encerramos a nossa série de artigos sobre Atlas Search! Espero que tenham gostado
Fonte: https://www.mongodb.com/developer/languages/csharp/vector-search-with-csharp-driver/






