




Fala galera, blz? Hoje vou falar um pouco sobre Document Model ou Modelo Orientado a Documento.
Esse tipo de modelo de dados é um dos pilares do NoSQL, o banco que utilizo no meu dia-a-dia é o MongoDB. Um banco de dados NoSQL open-source com uma comunidade gigantesca espalhada pelo mundo, confira mais aqui.
Quando o Document Model é uma boa?
Bem, é uma pergunta relativa… o document model pode ser encaixado em vários cenários, porém, sempre ressalto que não serve pra tudo. Quando estamos modelando uma aplicação devemos pensar sempre em como vamos querer exibir nossos dados. Claro que no meio desse planejamento podemos preferir dar mais performance para escrita ou em outros casos para leitura, mas uma hora teremos que decidir o que será mais importante para nosso produto final.
Tenho utilizado o document model para várias aplicações nos últimos anos, desde as mais simples até aplicações complexas que exigem um grande número de escrita ou leitura dos dados, e tenho observado que esse tipo de modelo se aplica muito bem em diferentes situações.
Por experiência própria de anos desenvolvendo em cima de bancos relacionais como o MS SQL Server, vi que um dos maiores ofensores de performance nas aplicações são os nossos queridos JOINs. No modelo relacional utilizamos os JOINs para relacionar uma ou várias tabelas do nosso modelo, isso pode causar perda de performance em alguns casos. No modelo de documentos temos o que chamamos de agregado, ou seja, trazemos para um único documento os dados que teríamos espalhados em várias tabelas. Vejamos um exemplo:
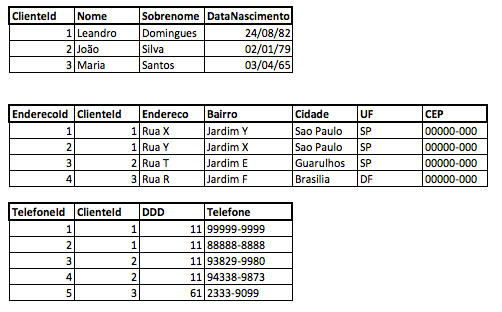
Na figura acima temos a representação de um modelo relacional com três tabelas, nesse caso faremos o relacionamento através o ClienteId. No document model esse mesmo modelo ficaria representado assim:
{
"clienteId": 1,
"nome": "Leandro",
"sobrenome": "Domingues",
"dataNascimento": ISODate("1982-08-24T00:00:00.000Z"),
"enderecos":[
{
"endereco": "Rua X",
"bairro": "Jardim Y",
"cidade": "Sao Paulo",
"uf": "SP",
"cep": "00000-000"
},
{
"endereco": "Rua Y",
"bairro": "Jardim X",
"cidade": "Sao Paulo",
"uf": "SP",
"cep": "00000-000"
}
],
"telefones": [
{
"ddd": 11,
"telefone": "99999-9999"
},
{
"ddd": 11,
"telefone": "88888-8888"
}
]
},
{
"clienteId": 2,
"nome": "João",
"sobrenome": "Silva",
"dataNascimento": ISODate("1979-01-02T00:00:00.000Z"),
"enderecos":[
{
"endereco": "Rua T",
"bairro": "Jardim E",
"cidade": "Guarulhos",
"uf": "SP",
"cep": "00000-000"
}
],
"telefones": [
{
"ddd": 11,
"telefone": "93829-9980"
},
{
"ddd": 11,
"telefone": "94338-9873"
}
]
},
{
"clienteId": 3,
"nome": "Maria",
"sobrenome": "Santos",
"dataNascimento": ISODate("1965-04-03T00:00:00.000Z"),
"enderecos":[
{
"endereco": "Rua R",
"bairro": "Jardim F",
"cidade": "Brasília",
"uf": "DF",
"cep": "00000-000"
}
],
"telefones": [
{
"ddd": 61,
"telefone": "2333-9099"
}
]
}
Uma das possibilidades existentes no document model, é a de agregar conteúdo ao nosso documento principal, nesse caso podemos ter arrays contendo outros documentos, como no caso dos endereços e telefones.
E o desenvolvimento como fica?
Na minha opinião esse modelo de dados veio para ajudar e muito os desenvolvedores, claro que para queries mais complexas é altamente aconselhável a análise de um DBA, porém, para queries mais simples o desenvolvedor se sentirá muito mais familiarizado com o JSON.
Agregando o conteúdo a um único documento, podemos ter chaves de pesquisa mais simples, retornando em nossas consultas todo o conteúdo do documento.
Obviamente, dependendo da quantidade de dados armazenada em um documento, teremos que utilizar de alguns recursos disponíveis no MongoDB para otimizar o retorno de nossa query. Por exemplo se quisermos retornar somente os endereços do cliente 1 poderíamos utilizar a seguinte query:
db.clientes.find({clienteId: 1}, {enderecos: 1})
Nessa query, dizemos ao MongoDB para nos retornar o cliente 1, porém, como segundo parâmetro da função especificamos qual campo de nossa coleção queremos no retorno, nesse caso, escolhemos o endereço. Nesse parâmetro podemos colocar vários campos para serem retornados:
db.clientes.find({clienteId: 1}, {nome:1, enderecos:1})
Nota: no MongoDB os documentos são armazenados no formato BSON. Cada documento tem o tamanho máximo de 16MB, esse limite ajuda a assegurar que um único documento não utilizará muita memória RAM ou exagere no tráfego de rede. Para conhecer mais sobre os limites de um documento veja aqui.
Conclusão
Bem, como disse no início o modelo orientado a documentos é muito legal, porém, não resolve todos os problemas. Devemos pensar muito bem antes de começar a modelar nossa aplicação.
Vale a pena olhar esse modelo de dados!
Espero que tenham gostado e até mais!
Referência: MongoDB Docs



: o que mudou e o que continua valendo")

